NEW: PySpaces Library
This page contains a summary of the PySpaces Python library that’s been developed to enhance the user experience of leveraging Python within the Spaces framework.
PySpaces
The pyspaces library provides an intuitive interface for leveraging Data Products and Assets within Spaces, allowing you to quickly :
Understand the data content of your space and how this is exposed to the Python environment
Create data frames from SQL expressions using either the Trino or Spark execution frameworks
Persist output data sets into the space collaborate and publish data bases via SQL statements and parameterised inputs
The library also provides in-line guidance and execution information to help you optimise your analytics processes within Spaces.
The PySpaces library is also fully supported within Tasks
The PySpaces library contains a number of modules which are outlined below, along with the supported methods within each module.
The library is pre-installed in all Spaces python environments, so to leverage the library you can import it directly at the top of your Jupyter notebooks
from pyspaces import spaces_trino
from pyspaces import spaces_spark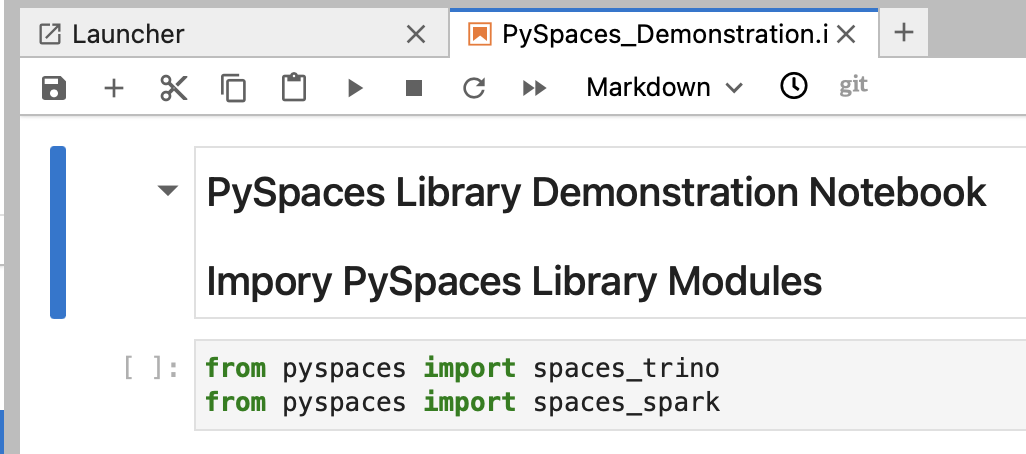
Library Module imp
Module : spaces_trino
This module provides methods that initiate and enable actions using the Trino execution engine, which provides high performance query execution across tabular data assets.
Trino is the recommended query engine within Spaces - start your analysis using this module before progressing to other mechanisms if required by your use case
trino_session()
Create a Trino session to use for you analysis. The returned object should be used as a connection entry in subsequent calls to the spaces_trino methods.
It is recommended to only create one trino_session per notebook
Options :
None
Returns : A Trino session connection object to be used to in subsequent calls to spaces_trino methods described below
Example
conn = spaces_trino.trinoSession()listSchemas(trino_connection)
List all the schemas defined in Trino based on the connection generated above.
Options :
trino_connection : the connection object returned by trinoSession()
Returns : A list with each available schema name stored as a string.
Example
schemas = spaces_trino.listSchemas(conn)listSchemaTables(trino_connection,schema)
List the tables within a named schema.
Options :
trino_connection : the connection object returned by trinoSession()
schema : schema name as a string
Returns : A list with each available table name stored as a string
Example
tables = spaces_trino.listSchemeTables(conn,"example_schema_1")describeTable(trino_connection,schema,table)
Describe a table within a schema
Options :
trino_connection : the connection object returned by trinoSession()
schema : schema name as a string
table: table name as a string
Returns : A pandas dataframe containing the table schema with columns “Field Name” and “Data Type”
Example
table_structure_df = spaces_trino.describeTable(conn,"example_schema_1",\
"example_table_1")createPandasDf(sql_statement, trino_connection, limit=None, check_output_size=True, output_size_control='strict')
Create a Pandas dataframe based on the results of a SQL select statement.
Data Product and Asset tables may be large and beyond what is possible to load into a single Pandas DataFrame.
To prioritise stability, the Default behaviour of the spaces_trino module is to prevent returns of results sets of more than 500,000 records and instead provide a warning and recommendation to leverage the createSparkDf() action as an alternative for larger data sets.
This behaviour can be overridden with the options described below, but these actions should be taken with caution and may introduce instability to your sessions.
Options :
sql_statement : Any valid SQL expression. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
trino_connection : the connection object returned by trinoSession()
limit (optional, Default = None) : apply a SQL limit statement to the results returned by your query with the number of records specified
check_output_size (optional, Default = True) : Boolean flag to define whether to perform a check on the number of records that will be returned before creating the Pandas DataFrame
output_size_control (optional, Default = ‘strict’) : Flag that determines whether the pandas DataFrame will be created based on the size of the Query result.
When set to ‘strict’ the dataframe will not be created and a warning will be returned.
When set to ‘attempt’ the dataframe will be created with warnings - this option should be used with caution as it may cause session stability issues in the case of large results sets.
Returns : A Pandas Dataframe containing the results of the SQL execution.
Example
Standard data frame create
sql = """
select * from example_schema_1.example_table_1 where country_code = 'GB'
"""
df = spaces_trino.createPandasDf(sql,conn)Standard data frame create with parameterised SQL
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
df = spaces_trino.createPandasDf(sql,conn)Parameterising your SQL statements can make your notebooks more efficient, interpretable and flexible
Use triple quote wrapping for SQL statements to express complex statements over multiple lines
Create data frame with size control options disabled (see above for details)
sql = """
select * from example_schema_1.example_table_1 where country_code = 'GB'
"""
df = spaces_trino.createPandasDf(sql,conn,check_output_size=True,\
output_size_control='attempt')createSparkDf(sql_statement, trino_connection, limit=None, check_output_size=True, output_size_control='strict')
Create a Spark dataframe based on the results of a SQL select statement.
Spark DataFrames are distributed across your Space session compute cluster, allowing for the loading of larger data volumes compared to Pandas. This method is the recommended approach for creating data frames from queries with large results sets.
Whilst not identical, Spark data frames can be used and manipulated in a similar manner to Pandas. See https://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html for general guidance on Spark DataFrames and https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html for guidance on leveraging Pandas methods directly against Spark DataFrames.
Options :
sql_statement : Any valid SQL expression. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
trino_connection : the connection object returned by trinoSession()
limit (optional, Default = None) : apply a SQL limit statement to the results returned by your query with the number of records specified
check_output_size (optional, Default = True) : Boolean flag to define whether to perform a check on the number of records that will be returned before creating the Spark DataFrame
Returns : A Spark dataframe containing the results of the SQL execution
Example
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spark_df = spaces_trino.createSparkDf(sql,conn)createTableFromSqlSelect(user_select_sql, trino_connection, output_schema=”collaborate_db”, output_table=None, drop_table=True, output_format=”parquet”)
Creates an output table in the provided schema using as Create Table As Select (CTAS) statement with the provided SQL select expression.
Options :
user_select_sql : Any valid SQL select statement. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
trino_connection : the connection object returned by trinoSession()
output_schema (Default = “collaborate_db”) : The schema to write the output table in, valid values :
collaborate_db
publish_db
output_table : The name of the output table being written. Required, process will return without exerting if not provided
drop_table (Optional, Default = True) : Boolean flag which determines whether to perform a drop table if exists command prior to creating the new table. Recommended for development and automation to prevent table exists errors on create attempt.
output_format (Optional, Default = “parquet”) : Format with which to store the output data sets. Supported Formats :
parquet (Default)
orc
avro
csv
textfile
json
rctext
rcbinary
Returns : Record count of created table as an Integer, with INFO messages printed to screen / log
Example
Fully Qualified create table action creating an output table derived_table_1 in the schema publish_db and stored as Avro format.
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spaces_trino.createTableFromSqlSelect(
sql,
conn,
output_schema="publish_db",
output_table="derived_table_1",
drop_table=True,
output_format="avro"
)The createTableFromSqlSelect method generates the broader create (and drop) SQL DDL commands and wraps them around your SQL statement based on the option inputs to the method.
So you can focus your SQL development on extracting value in your use case, whilst the library handles the database and schema interactions 👍
Partially qualified SQL create table action creating an output table derived_table_2 in the default schema collaborate_db and stored as the default Parquet format.
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spaces_trino.createTableFromSqlSelect(
sql,
conn,
output_table="derived_table_2"
)Module : spaces_spark
This module provides methods that initiate and enable actions using the Spark execution engine, which provides powerful distributed processing for query and analytical purposes.
Trino is the recommended query engine within Spaces - Spark should be used when performing analyical workloads not supported by Trino, AI / Machine learning projects and interacting with large volume non-tabular file assets.
spark_session()
Validates that your notebook has an active Spark session from the JupyterLab kernel and provides details.
Options :
None
Returns : Diagnostics showing your Spark session and any remediation actions required if you do not currently have a Spark session.
Example
spaces_spark.sparkSession()listSchemas(spark_session)
List all the schemas defined in Spark based on the active Spark session.
The Spark session is only able to access on-platform assets and the collaborate and publish data bases.
If you need to leverage an at-source asset within Spark, utilise the spaces_trino.createSparkDataFrame() method to build a Spark data frame against the remote connection via Trino.
Options :
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
Returns : A list with each available schema name stored as a string.
Example
schemas = spaces_spark.listSchemas(spark)listSchemaTables(spark_session,schema)
List the tables within a named schema.
Options :
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
schema : schema name as a string
Returns : A list with each available table name stored as a string
Example
tables = spaces_spark.listSchemeTables(spark,"example_schema_1")describeTable(spark_session,schema,table)
Describe a table within a schema
Options :
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
schema : schema name as a string
table: table name as a string
Returns : A pandas dataframe containing the table schema with columns “Field Name” and “Data Type”
Example
table_structure_df = spaces_spark.describeTable(spark,"example_schema_1",
"example_table_1")createPandasDf(sql_statement, spark_session, limit=None, check_output_size=True, output_size_control='strict')
Create a Pandas dataframe based on the results of a SQL select statement.
Data Product and Asset tables may be large and beyond what is possible to load into a single Pandas DataFrame.
To prioritise stability, the Default behaviour of the spaces_spark module is to prevent returns of results sets of more than 500,000 records and instead provide a warning and recommendation to leverage the createSparkDf() action as an alternative for larger data sets.
This behaviour can be overridden with the options described below, but these actions should be taken with caution and may introduce instability to your sessions.
Options :
sql_statement : Any valid SQL expression. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
limit (optional, Default = None) : apply a SQL limit statement to the results returned by your query with the number of records specified
check_output_size (optional, Default = True) : Boolean flag to define whether to perform a check on the number of records that will be returned before creating the Pandas DataFrame
output_size_control (optional, Default = ‘strict’) : Flag that determines whether the pandas DataFrame will be created based on the size of the Query result.
When set to ‘strict’ the dataframe will not be created and a warning will be returned.
When set to ‘attempt’ the dataframe will be created with warnings - this option should be used with caution as it may cause session stability issues in the case of large results sets.
Returns : A Pandas Dataframe containing the results of the SQL execution.
Example
Standard data frame create
sql = """
select * from example_schema_1.example_table_1 where country_code = 'GB'
"""
df = spaces_spark.createPandasDf(sql,spark)Standard data frame create with parameterised SQL
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
df = spaces_spark.createPandasDf(sql,spark)Parameterising your SQL statements can make your notebooks more efficient, interpretable and flexible
Use triple quote wrapping for SQL statements to express complex statements over multiple lines
Create data frame with size control options disabled (see above for details)
sql = """
select * from example_schema_1.example_table_1 where country_code = 'GB'
"""
df = spaces_spark.createPandasDf(sql,spark,check_output_size=True,\
output_size_control='attempt')createSparkDf(sql_statement, spark_session, limit=None, check_output_size=True, output_size_control='strict')
Create a Spark dataframe based on the results of a SQL select statement.
Spark DataFrames are distributed across your Space session compute cluster, allowing for the loading of larger data volumes compared to Pandas. This method is the recommended approach for creating data frames from queries with large results sets.
Whilst not identical, Spark data frames can be used and manipulated in a similar manner to Pandas. See https://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html for general guidance on Spark DataFrames and https://spark.apache.org/docs/latest/api/python/user_guide/pandas_on_spark/index.html for guidance on leveraging Pandas methods directly against Spark DataFrames.
Options :
sql_statement : Any valid SQL expression. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
limit (optional, Default = None) : apply a SQL limit statement to the results returned by your query with the number of records specified
check_output_size (optional, Default = True) : Boolean flag to define whether to perform a check on the number of records that will be returned before creating the Spark DataFrame
Returns : A Spark dataframe containing the results of the SQL execution
Example
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spark_df = spaces_spark.createSparkDf(sql,spark)createTableFromSqlSelect(user_select_sql, spark_session, output_schema=”collaborate_db”, output_table=None, drop_table=True, output_format=”parquet”)
Creates an output table in the provided schema using as Create Table As Select (CTAS) statement with the provided SQL select expression.
Options :
user_select_sql : Any valid SQL select statement. See for https://trino.io/docs/current/language.html documentation on TrinoSQL syntax and supported functions.
spark_session : the predefined session named spark provided by the JupyterLab PySpark kernel.
output_schema (Default = “collaborate_db”) : The schema to write the output table in, valid values :
collaborate_db
publish_db
output_table : The name of the output table being written. Required, process will return without exerting if not provided
drop_table (Optional, Default = True) : Boolean flag which determines whether to perform a drop table if exists command prior to creating the new table. Recommended for development and automation to prevent table exists errors on create attempt.
output_format (Optional, Default = “parquet”) : Format with which to store the output data sets. Supported Formats :
parquet (Default)
orc
avro
csv
textfile
json
rctext
rcbinary
Returns : Record count of created table as an Integer, with INFO messages printed to screen / log
Example
Fully Qualified create table action creating an output table derived_table_1 in the schema publish_db and stored as Avro format.
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spaces_spark.createTableFromSqlSelect(
sql,
spark,
output_schema="publish_db",
output_table="derived_table_1",
drop_table=True,
output_format="avro"
)The createTableFromSqlSelect method generates the broader create (and drop) SQL DDL commands and wraps them around your SQL statement based on the option inputs to the method.
So you can focus your SQL development on extracting value in your use case, whilst the library handles the database and schema interactions 👍
Partially qualified SQL create table action creating an output table derived_table_2 in the default schema collaborate_db and stored as the default Parquet format.
read_schema = "example_schema_1"
read_table = "example_table_1"
sql = """
select
field1,
field2,
field3
from {read_schema}.{read_table}
where country_code = 'GB'
""".format(read_schema=read_schema,read_table=read_table)
spaces_spark.createTableFromSqlSelect(
sql,
spark,
output_table="derived_table_2"
)Release History
Version 1 - February 2024
Initial package with modules :
spaces_trino
spaces_spark